Message Passing and the Actor Model
Introduction
Message passing programming models have essentially been discussed since the beginning of distributed computing and as a result message passing can be taken to mean a lot of things. If you look up a broad definition on Wikipedia, it includes things like Remote Procedure Calls (RPC), and Message Passing Interface (MPI). Additionally, there are popular process-calculi like the pi-calculus and Communicating Sequential Processes (CSP) which have inspired practical message passing systems. For example, Go’s channels are based on the idea of first-class communication channels from the pi-calculus and Clojure’s core.async library is based on CSP. However, when people talk about message passing today they mostly mean the actor model. It is a ubiquitous and general message passing programming model that has been developing since the 1970’s and is used today to build massive scalable systems.
In the field of message passing programming models, it is not only important to consider recent state of the art research, but additionally the historic initial papers on message passing and the actor model that are the roots of the programming models described in more recent papers. It is enlightening to see which aspects of the models have stuck around, and many of the more recent papers reference and address deficiencies present in older papers. There have been plenty of programing languages designed around message passing, especially those focused on the actor model of programming and organizing units of computation.
In this chapter I describe the four primary variants of the actor model: classic actors, process-based actors, communicating event-loops, and active objects. I attempt to highlight historic and modern languages that exemplify these models, as well as the philosophies and tradeoffs that programmers need to be aware of to understand and best make use of these models.
Despite the actor model’s originating as far back as the 1970s, it is still being developed and being incorporated into the programming languages of today, as many recently published papers and systems in the field demonstrate. There are a few robust industrial-strength actor systems that are being used to power massive scalable distributed systems; for example Akka has been used to serve PayPal’s billions of transactions, (Sucharitakul, 2016) Erlang has been used to send messages for WhatsApp’s hundreds of millions of users, (Reed, 2012) and Orleans has been used to serve Halo 4’s millions of players. (McCaffrey, 2015) There are a couple of different approaches to building industrial actor frameworks around monitoring, handling fault-tolerance, and managing actor lifecycles which are detailed later in the chapter.
An important framing for the actor models presented is in the question “Why message passing, and specifically why the actor model?” Given the vast number of distributed programming models out there, one might ask, why this one was so important when it was initially proposed? Why has it facilitated advanced languages, systems, and libraries that are widely used today? As we’ll see throughout this chapter, some of the broadest advantages of the actor model include isolation of state managed by the given actor, scalability, and simplifying the programmer’s ability to reason about their system.
Original proposal of the actor model
The actor model was originally proposed in A Universal Modular ACTOR Formalism for Artificial Intelligence (Hewitt, Bishop, & Steiger, 1973) in 1973 as a method of computation for artificial intelligence research. The original goal of the model was to model parallel computation in communication in a way that could be safely distributed concurrently across workstations. The paper makes few presumptions about implementation details, instead defining the high-level message passing communication model. Gul Agha developed the model further, by focusing on using actors as a basis for concurrent object-oriented programming. This work is collected in Actors: A Model of Concurrent Computation in Distributed Systems. (Agha, 1986)
Actors are defined as independent units of computation with isolated state. These units have two core characteristics:
- they can send messages asynchronously to one another, and,
- they have a mailbox which contains messages that they have received, allowing messages to be received at any time and then queued for processing.
Messages are of the form:
(request: <message-to-target>
reply-to: <reference-to-messenger>)
Actors attempt to process messages from their mailboxes by matching their request field sequentially against patterns or rules which can be specific values or logical statements. When a pattern is matched, computation occurs and the result of that computation is implicitly returned to the reference in the message’s reply-to field. This is a type of continuation, where the continuation is the message to another actor. These messages are one-way and, there are no guarantees that a message will ever be received in response. The actor model is so general because it places few restrictions on systems. Asynchrony and the absence of message delivery guarantees enable modeling real distributed systems using the actor model. For example, if message delivery was guaranteed, then the model would be much less general, and only able to model systems which include complex message-delivery protocols. This originally-proposed variant of the actor model is limited compared to many of the others, but the early ideas of taking advantage of distribution of processing power to enable greater parallel computation are there.
Interestingly, the original paper introducing the actor model does so in the context of hardware. They mention actors as almost another machine architecture. This paper describes the concepts of an “actor machine” and a “hardware actor” as the context for the actor model, which is totally different from the way we think about modern actors as abstracting away a lot of the hardware details we don’t want to deal with. This concept is reminiscent of something like a Lisp machine, though specially built to utilize the actor model of computation for artificial intelligence.
Classic actor model
The classic actor model was formalized as a unit of computation in Agha’s Concurrent Object-Oriented Programming. (Agha, 1990) The classic actor expands on the original proposal of actors, keeping the ideas of asynchronous communication through messages between isolated units of computation and state. The classic actor contains the following primitive operations:
create: create an actor from a behavior description and a set of parameters, including other existing actorssend: send a message to another actorbecome: have an actor replace their behavior with a new one
As in the original actor model, classic actors communicate by asynchronous message passing. They are a primitive independent unit of computation which can be used to build higher-level abstractions for concurrent programming. Actors are uniquely addressable, and have their own independent mailboxes or message queues. State changes using the classic actor model are specified and aggregated using the become operation. Each time an actor processes a message it computes a behavior in response to the next type of message it expects to process. A become operation’s argument is a named continuation, b, representing behavior that the actor should be updated with, along with some state that should be passed to b.
This continuation model is flexible. You could create a purely functional actor where the new behavior would be identical to the original and no state would be passed. An example of this is the AddOne actor below, which processes a message according to a single fixed behavior.
(define AddOne
[add-one [n]
(return (+ n 1))])
The model also enables the creation of stateful actors which change behavior and pass along an object representing some state. This state can be the result of many operations, which enables the aggregation of state changes at a higher level of granularity than something like variable assignment. An example of this is a BankAccount actor given in Concurrent Object-Oriented Programming. (Agha, 1990)
(define BankAccount
(mutable [balance]
[withdraw-from [amount]
(become BankAccount (- balance amount))
(return 'withdrew amount)]
[deposit-to [amount]
(become BankAccount (+ balance amount))
(return 'deposited amount)]
[balance-query
(return 'balance-is balance)]))
Stateful continuations enable flexibility in the behavior of an actor over time in response to the actions of other actors in the system. Limiting state and behavior changes to become operations changes the level at which one analyzes a system, freeing the programmer from worrying about interference during state changes. In the example above, the programmer only has to worry about changes to the account’s balance during become statements in response to a sequential queue of well-defined message types.
If you squint a little, this actor definition sounds similar to Alan Kay’s original definition of Object Oriented programming. This definition describes a system where objects have a behavior, their own memory, and communicate by sending and receiving messages that may contain other objects or simply trigger actions. Kay’s ideas sound closer to what we consider the actor model today, and less like what we consider object-oriented programming. That is, Kay’s focus in this description is on designing the messaging and communications that dictate how objects interact.
The big idea is "messaging" -- that is what the kernal [sic] of Smalltalk/Squeak is all about (and it's something that was never quite completed in our Xerox PARC phase). The Japanese have a small word -- ma -- for "that which is in between" -- perhaps the nearest English equivalent is "interstitial". The key in making great and growable systems is much more to design how its modules communicate rather than what their internal properties and behaviors should be.
Concurrent Object-Oriented Programming (1990)
One could say that the renaissance of actor models in mainstream program began with Gul Agha’s work. His seminal book Actors: A Model of Concurrent Computation in Distributed Systems (Agha, 1986) and later paper, Concurrent Object-Oriented Programming (Agha, 1990), offer classic actors as a natural solution to solving problems at the intersection of two trends in computing; increased distributed computing resources and the rising popularity of object-oriented programming. The paper defines common patterns of parallelism: pipeline concurrency, divide and conquer, and cooperative problem solving. It then focuses on how the actor model can be used to solve these problems in an object-oriented style, and some of the challenges that arise with distributed actors and objects, as well as strategies and tradeoffs for communication and reasoning about behaviors.
This paper looks at a lot of systems and languages that are implementing solutions in this space, and starts to identify some of the advantages from the perspective of programmers of programming with actors. One of the core languages used for examples in the paper is Rosette (Tomlinson et al., 1988), but the paper largely focuses on the potential and benefits of the model. Agha claims the benefits of using objects stem from a separation of concerns.
By separating the specification of what is done (the abstraction) from how it is done (the implementation), the concept of objects provides modularity necessary for programming in the large. It turns out that concurrency is a natural consequence of the concept of objects.
Splitting concerns into multiple pieces allows for the programmer to have an easier time reasoning about the behavior of the program. It also allows the programmer to use more flexible abstractions in their programs.
It is important to note that the actor languages give special emphasis to developing flexible program structures which simplify reasoning about programs.
This flexibility turns out to be a highly discussed advantage which continues to be touted in modern actor systems.
Rosette
Rosette was both a language for concurrent object-oriented programming of actors, as well as a runtime system for managing the usage of and access to resources by those actors. Rosette (Tomlinson et al., 1988) is mentioned throughout Agha’s Concurrent Object-Oriented Programming, (Agha, 1990) and the code examples given in the paper are written in Rosette. Agha is even an author on the Rosette paper, so its clear that Rosette is foundational to the classic actor model. It seems to be a language which almost defines what the classic actor model looks like in the context of concurrent object-oriented programming.
The motivation behind Rosette was to provide strategies for dealing with problems like search, where the programmer needs a means to control how resources are allocated to sub-computations to optimize performance in the face of combinatorial explosion. For example in a search problem, you might first compute an initial set of results that you want to further refine. It would be too computationally expensive to exhaustively refine every result, so you want to choose the best ones based on some metric and only proceed with those. Rosette supports the use of concurrency in solving computationally intensive problems whose structure is not statically defined, but rather depends on some heuristic to return results. Rosette has an architecture which uses actors in two distinct ways. They describe two different layers with different responsibilities:
- Interface layer: This implements mechanisms for monitoring and control of resources. The system resources and hardware are viewed as actors.
- System environment: This is comprised of actors who actually describe the behavior of concurrent applications and implement resource management policies based on the interface layer.
The Rosette language has a number of object-oriented features, many of which we take for granted in modern object-oriented programming languages. It implements dynamic creation and modification of objects for extensible and reconfigurable systems, supports inheritance, and has objects which can be organized into classes. The more interesting characteristic is that the concurrency in Rosette is inherent and declarative rather than explicit as with many modern object-oriented languages. In Rosette, the concurrency is an inherent property of the program structure and resource allocation. This is different from a language like Java, where all of the concurrency is very explicit. The Java concurrency model is best covered in Java Concurrency in Practice, though Java 8 introduces a few new concurrency techniques that the book does not discuss. (Peierls et al., 2005) The motivation behind this declarative concurrency comes from the heterogeneous nature of distributed concurrent computers. Different computers and architectures have varying concurrency characteristics, and the authors argue that forcing the programmer to tailor their concurrency to the specific machine makes it difficult to re-map a program to another one. This idea of using actors as a more flexible and natural abstraction over concurrency and distribution of resources is an important one which is seen in some form within many actor systems.
Actors in Rosette are organized into three types of classes which describe different aspects of the actors within the system:
- Abstract classes specify requests, responses, and actions within the system which can be observed. The idea behind these is to expose the higher-level behaviors of the system, but tailor the actual actor implementations to the resource constraints of the system.
- Representation classes specify the resource management characteristics of implementations of abstract classes.
- Behavior classes specify the actual implementations of actors in given abstract and representation classes.
These classes represent a concrete object-oriented abstraction to organize actors which handles the practical constraints of a distributed system. It represents a step in the direction of handling not just the information flow and behavior of the system, but the underlying hardware and resources. Rosette’s model feels like a direct expression of those concerns which are something every actor system in production inevitably ends up addressing.
Akka
Akka is an effort to bring an industrial-strength actor model to the JVM runtime, which was not explicitly designed to support actors. Akka was developed out of initial efforts of Scala Actors to bring the actor model to the JVM. There are a few notable changes from Scala Actors that make Akka worth mentioning, especially as it is being actively developed while Scala Actors is not. Some important changes are detailed in On the Integration of the Actor Model in Mainstream Technologies: The Scala Perspective. (Haller, 2012)
Akka provides a programming interface with both Java and Scala bindings for actors which looks similar to Scala Actors, but has different semantics in how it processes messages. Akka’s receive operation defines a global message handler which doesn’t block on the receipt of no matching messages, and is instead only triggered when a matching message can be processed. It also will not leave a message in an actor’s mailbox if there is no matching pattern to handle the message. The message will simply be discarded and an event will be published to the system. Akka’s interface also provides stronger encapsulation to avoid exposing direct references to actors. Akka actors have a limited ActorRef interface which only provides methods to send or forward messages to its actor, additionally checks are done to ensure that no direct reference to an instance of an Actor subclass is accessible after an actor is created. To some degree this fixes problems in Scala Actors where public methods could be called on actors, breaking many of the guarantees programmers expect from message-passing. This system is not perfect, but in most cases it limits the programmer to simply sending messages to an actor using a limited interface.
The Akka runtime also provides performance advantages over Scala Actors. The runtime uses a single continuation closure for many or all messages an actor processes, and provides methods to change this global continuation. This can be implemented more efficiently on the JVM, as opposed to Scala Actors’ continuation model which uses control-flow exceptions which cause additional overhead. Additionally, nonblocking message insert and task schedule operations are used for extra performance.
Akka is the production-ready result of the classic actor model lineage. It is actively developed and actually used to build scalable systems. The production usage of Akka is detailed later in this chapter. Akka has been successful enough that it has been ported to other languages/runtimes. There is an Akka.NET project which brings the Akka programming model to .NET and Mono using C# and F#. Akka has even been ported to JavaScript as Akka.js, built on top of Scala.js.
Process-based actors
The process-based actor model is essentially an actor modeled as a process that runs from start to completion. This view is broadly similar to the classic actor, but different mechanics exist around managing the lifecycle and behaviors of actors between the models. The first language to explicitly implement this model is Erlang, (Armstrong, 2010) and they even say in a retrospective that their view of computation is broadly similar to the Agha’s classic actor model.
Process-based actors are defined as a computation which runs from start to completion, rather than the classic actor model, which defines an actor almost as a state machine of behaviors and the logic to transition between those. Similar state-machine like behavior transitions are possible through recursion with process-based actors, but programming them feels fundamentally different than using the previously described become statement.
These actors use a receive primitive to specify messages that an actor can receive during a given state/point in time. receive statements have some notion of defining acceptable messages, usually based on patterns, conditionals or types. If a message is matched, corresponding code is evaluated, but otherwise the actor simply blocks until it gets a message that it knows how to handle. The semantics of this receive are different than the receive previously described in the section about Akka. Akka’s receive is explicitly only triggered when an actor gets a message it knows how to handle. Depending on the language implementation receive might specify an explicit message type or perform some pattern matching on message values.
An example of these core concepts of a process with a defined lifecycle and use of the receive statement to match messages is a simple counter process written in Erlang. (Armstrong, 2010)
counter(N) ->
receive
tick ->
counter(N+1);
{From, read} ->
From ! {self(), N},
counter(N)
end.
This demonstrates the use of receive to match on two different values of messages tick, which increments the counter, and {From, read} where From is a process identifier and read is a literal. In response to another process sending the message tick by doing something like CounterId ! tick. the process calls itself with an incremented value which demonstrates a similarity to the become statement, but using recursion and an argument value instead of a named behavior continuation and some state. If the counter receives a message of the form {<processId>, read} it will then send that process a message with the counter’s processId and value, and call itself recursively with the same value.
Erlang
Erlang’s implementation of process-based actors gets to the core of what it means to be a process-based actor. Erlang was the origin of the process-based actor model. The Ericsson company originally developed this model to program large highly-reliable fault-tolerant telecommunications switching systems. Erlang’s development started in 1985, but its model of programming is still used today. The motivations of the Erlang model were around four key properties that were needed to program fault-tolerant operations:
- Isolated processes
- Pure message passing between processes
- Detection of errors in remote processes
- The ability to determine what type of error caused a process crash
The Erlang researchers initially believed that shared-memory was preventing fault-tolerance and they saw message-passing of immutable data between processes as the solution to avoiding shared-memory. There was a concern that passing around and copying data would be costly, but the Erlang developers saw fault-tolerance as a more important concern than performance. This model was essentially developed independently from other actor systems and research, especially as its development was started before Agha’s classic actor model formalization was even published, but it ends up with a broadly similar view of computation to Agha’s classic actor model.
Erlang actors run as lightweight isolated processes. They do not have visibility into one another, and pass around pure messages, which are immutable. These have no dangling pointers or data references between objects, and really enforce the idea of immutable separated data between actors unlike many of the early classic actor implementations in which references to actors and data can be passed around freely.
Erlang implements a blocking receive operation as a means of processing messages from a processes’ mailbox. They use value matching on message tuples as a means of describing the types of messages a given actor can accept.
Erlang also seeks to build failure into the programming model, as one of the core assumptions of a distributed system is that machines and network connections are going to fail. Erlang provides the ability for processes to monitor one another through two primitives:
monitor: one-way unobtrusive notification of process failure/shutdownlink: two-way notification of process failure/shutdown allowing for coordinated termination
These primitives can be used to construct complex hierarchies of supervision that can be used to handle failure in isolation, rather than failures impacting your entire system. Supervision hierarchies are notably almost the only scheme for fault-tolerance that exists in the world of actors. Almost every actor system that is used to build distributed systems takes a similar approach, and it seems to work. Erlang’s philosophies used to build a reliable fault-tolerant telephone exchange seem to be broadly applicable to the fault-tolerance problems of distributed systems.
An example of a process monitor written in Erlang is given below. (Armstrong, 2010)
on_exit(Pid, F) ->
spawn(fun() -> monitor(Pid, F) end).
monitor(Pid, F) ->
process_flag(trap_exit, true),
link(Pid),
receive
{‘EXIT’, Pid, Why} ->
F(Why)
end.
This defines two processes: on_exit which simply spawns a monitor process to call a given function when a given process id exits, and monitor which uses link to receive a message when the given process id exists, and to call a function with the reason it exited. You could imagine chaining many of these monitor and link operations together to build processes to monitor one another for failure and perform recovery operations depending on the failure behavior.
It is worth mentioning that Erlang achieves all of this through the Erlang Virtual Machine (BEAM), which runs as a single OS process and OS thread per core. These single OS processes then manage many lightweight Erlang processes. The Erlang VM implements all of the concurrency, monitoring, and garbage collection for Erlang processes within this VM, which almost acts like an operating system itself. This is unlike any other language or actor system described here.
Scala Actors
Scala Actors is an example of taking and enhancing the Erlang model while bringing it to a new platform. Scala Actors brings lightweight Erlang-style message-passing concurrency to the JVM and integrates it with the heavyweight thread/process concurrency models. (Haller & Odersky, 2009) This is stated well in the original paper about Scala Actors as “an impedance mismatch between message-passing concurrency and virtual machines such as the JVM.” VMs usually map threads to heavyweight processes, but that a lightweight process abstraction reduces programmer burden and leads to more natural abstractions. The authors claim that “The user experience gained so far indicates that the library makes concurrent programming in a JVM-based system much more accessible than previous techniques.”
The realization of this model depends on efficiently multiplexing actors to threads. This technique was originally developed in Scala actors, and later was adopted by Akka. This integration allows for Actors to invoke methods that block the underlying thread in a way that doesn’t prevent actors from making process. This is important to consider in an event-driven system where handlers are executed on a thread pool, because the underlying event-handlers can’t block threads without risking thread pool starvation. The end result here is that Scala Actors enabled a new lightweight concurrency primitive on the JVM, with enhancements over Erlang’s model. The Erlang model was further enhanced with Scala’s pattern-matching capabilities which enable more advanced pattern-matching on messages compared to Erlang’s tuple value matching. Scala Actors are of the type Any => Unit, which means that they are essentially untyped. They can receive literally any type and match on it with potential side effects. This behavior could be problematic and systems like Cloud Haskell and Akka aim to improve on it. Akka especially directly draws on the work of Scala Actors, and has now become the standard actor framework for Scala programmers.
Cloud Haskell
Cloud Haskell is an extension of Haskell which essentially implements an enhanced version of the computational message-passing model of Erlang in Haskell. (Epstein, Black, & Peyton-Jones, 2011) It enhances Erlang’s model with advantages from Haskell’s model of functional programming in the form of purity, types, and monads. Cloud Haskell enables the use of pure functions for remote computation, which means that these functions are idempotent and can be restarted or run elsewhere in the case of failure without worrying about side-effects or undo mechanisms. This alone isn’t so different from Erlang, which operates on immutable data in the context of isolated memory.
One of the largest improvements over Erlang is the introduction of typed channels for sending messages. These provide guarantees to the programmer about the types of messages their actors can handle, which is something Erlang lacks. In Erlang, all you have is dynamic pattern matching based on values patterns, and the hope that the wrong types of message don’t get passed around your system. Cloud Haskell processes can also use multiple typed channels to pass messages between actors, rather than Erlang’s single untyped channel. Haskell’s monadic types make it possible for programmers to use a programming style, where they can ensure that pure and effective code are not mixed. This makes reasoning about where side-effects happen in your system easier. Cloud Haskell has shared memory within an actor process, which is useful for certain applications. This might sound like it could cause problems, but shared-memory structures are forbidden by the type system from being shared across actors. Finally, Cloud Haskell allows for the serialization of function closures, which means that higher-order functions can be distributed across actors. This means that as long as a function and its environment are serializable, they can be spun off as a remote computation and seamlessly continued elsewhere. These improvements over Erlang make Cloud Haskell a notable project in the space of process-based actors. Cloud Haskell is currently supported and also has developed the Cloud Haskell Platform, which aims to provide common functionality needed to build and manage a production actor system using Cloud Haskell.
Communicating event-loops
The communicating event-loop model was introduced in the E language, (Miller, Tribble, & Shapiro, 2005) and is one that aims to change the level of granularity at which communication happens within an actor-based system. The previously described actor systems organize communication at the actor level, while the communicating event model puts communication between actors in the context of actions on objects within those actors. The overall messages still reference higher-level actors, but those messages refer to more granular actions within an actor’s state.
E Language
The E language implements a model which is closer to imperative object-oriented programming. Within a single actor-like node of computation called a “vat” many objects are contained. This vat contains not just objects, but a mailbox for all of the objects inside, as well as a call stack for methods on those objects. There is a shared message queue and event-loop that acts as one abstraction barrier for computation across actors. The actual references to objects within a vat are used for addressing communication and computation across actors and operate at a different level of abstraction.
This immediately raises other concerns. When handing out references at a different level of granularity than actor-global, how do you ensure the benefits of isolation that the actor model provides? After all, by referencing objects inside of an actor from many places it sounds like we’re just reinventing shared-memory problems. This is answered by two different modes of execution: immediate and eventual calls.
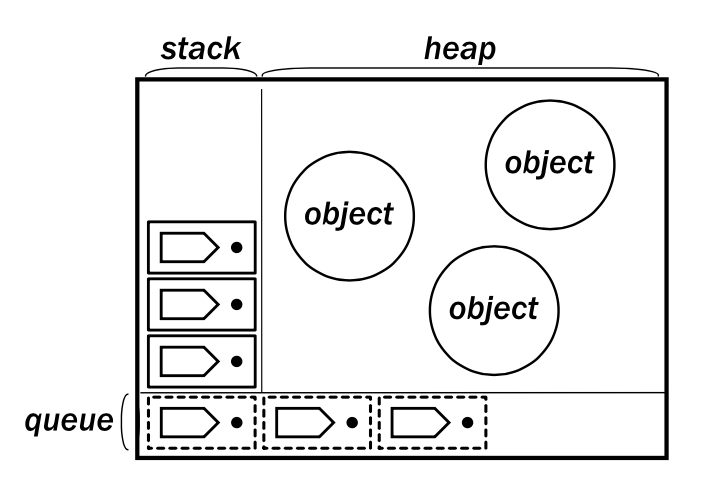
This diagram shows an E vat, which consists of a heap of objects and a thread of control for executing methods on those objects. The stack and queue represent messages in the two different modes of execution that are used when operating on objects in E. The stack is used for immediate execution, while the queue is used for eventual execution. Immediate calls are processed first, and new immediate calls are added to the top of the stack. Eventual calls are then processed from the queue afterwards. These different modes of message passing are highlighted in communication across vats below.
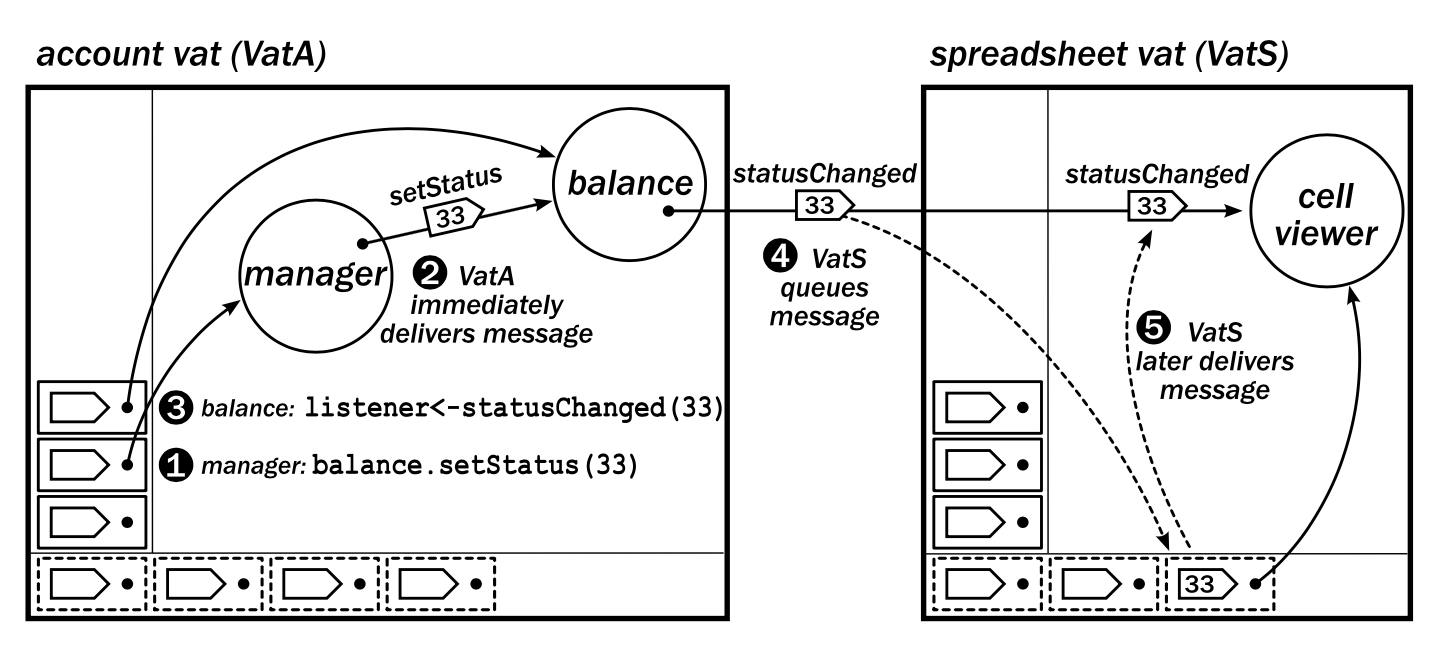
From this diagram we can see that local calls among objects within a vat are handled on the immediate stack. Then when a call needs to be made across vats, it is handled on the eventual queue, and delivered to the appropriate object within the vat at some point in the future.
E’s reference-states define many of the isolation guarantees around computation that we expect from actors. Two different ways to reference objects are defined:
- Near reference: This is a reference only possible between two objects in the same vat. These expose both synchronous immediate-calls and asynchronous eventual-sends.
- Eventual reference: This is a reference which crosses vat boundaries, and only exposes asynchronous eventual-sends, not synchronous immediate-calls.
The difference in semantics between the two types of references means that only objects within the same vat are granted synchronous access to one another. The most an eventual reference can do is asynchronously send and queue a message for processing at some unspecified point in the future. This means that within the execution of a vat, a degree of temporal isolation can be defined between the objects and communications within the vat, and the communications to and from other vats.
This code example ties into the previous diagrams, and demonstrates the two different types reference semantics. (Miller, Tribble, & Shapiro, 2005)
def makeStatusHolder(var myStatus) {
def myListeners := [].diverge()
def statusHolder {
to addListener(newListener) {
myListeners.push(newListener)
}
to getStatus() { return myStatus }
to setStatus(newStatus) {
myStatus := newStatus
for listener in myListeners {
listener <- statusChanged(newStatus)
}
}
}
return statusHolder
}
This creates an object statusHolder with methods defined by to statements. A method invocation from another vat-local object like statusHolder.setStatus(123) causes a message to be synchronously delivered to this object. Other objects can register as event listeners by calling either statusHolder.addListener() or statusHolder <- addListener() to either synchronously or eventually register as listeners. They will be notified eventually when the value of the statusHolder changes. This is done via <- which is the eventual-send operator.
The motivation for this referencing model comes from wanting to work at a finer-grained level of references than a traditional actor exposes. The simplest example is that you want to ensure that another actor in your system can read a value, but can’t write to it. How do you do that within another actor model? You might imagine creating a read-only variant of an actor which doesn’t expose a write message type, or proxies only read messages to another actor which supports both read and write operations. In E because you are handing out object references, you would simply only pass around references to a read method, and you don’t have to worry about other actors in your system being able to write values. These finer-grained references make reasoning about state guarantees easier because you are no longer exposing references to an entire actor, but instead the granular capabilities of the actor. Finer-grained references also enable partial failures and recoveries within an actor. Individual objects within an actor can fail and be restarted without affecting the health of the entire actor. This is in a way similar to the supervision hierarchies seen in Erlang, and even means that messages to a failed object could be queued for processing while that object is recovering. This is something that could not happen with the same granularity in another actor system, but feels like a natural outcome of object-level references in E.
AmbientTalk/2
AmbientTalk/2 is a modern revival of the communicating event-loops actor model as a distributed programming language with an emphasis on developing mobile peer-to-peer applications. (Cutsem, Mostinckx, Boix, Dedecker, & Meuter, 2007) This idea was originally realized in AmbientTalk/1 (Dedecker, Van Cutsem, Mostinckx, D'Hondt, & De Meuter, 2006) where actors were modelled as ABCL/1-like active objects (Yonezawa, Briot, & Shibayama, 1986), but AmbientTalk/2 models actors similarly to E’s vats. The authors of AmbientTalk/2 felt limited by not allowing passive objects within an actor to be referenced by other actors, so they chose to go with the more fine-grained approach which allows for remote interactions between and movement of passive objects.
Actors in AmbientTalk/2 are representations of event loops. The message queue is the event queue, messages are events, asynchronous message sends are event notifications, and object methods are the event handlers. The event loop serially processes messages from the queue to avoid race conditions. Local objects within an actor are owned by that actor, which is the only entity allowed to directly execute methods on them. Like E, objects within an actor can communicate using synchronous or asynchronous methods of communication. Again similar to E, objects that are referenced outside of an actor can only be communicated to asynchronously by sending messages. Objects can additionally declare themselves serializable, which means they can be copied and sent to other actors for use as local objects. When this happens, there is no maintained relationship between the original object and its copy.
AmbientTalk/2 uses the event loop model to enforce three essential concurrency control properties:
- Serial execution: Events are processed sequentially from an event queue, so the handling of a single event is atomic with respect to other events.
- Non-blocking communication: An event loop doesn’t suspend computation to wait for other event loops, instead all communication happens strictly as asynchronous event notifications.
- Exclusive state access: Event handlers (object methods) and their associated state belong to a single event loop, which has access to their mutable state. Mutation of other event loop state is only possible indirectly by passing an event notification asking for mutation to occur.
The end result of all this decoupling and isolation of computation is that it is a natural fit for mobile ad hoc networks. In this domain, connections are volatile with limited range and transient failures. Removing coupling based on time or synchronization is a natural fit for the domain, and the communicating event-loop actor model is a natural model for programming these systems. AmbientTalk/2 provides additional features on top of the communicating event-loop model like service discovery. These enable ad hoc network creation as actors near each other can broadcast their existence and advertise common services that can be used for communication.
AmbientTalk/2 is most notable as a reimagining of the communicating event-loops actor model for a modern use case. This again speaks to the broader advantages of actors and their applicability to solving the problems of distributed systems.
Active Objects
Active object actors draw a distinction between two different types of objects: active and passive objects. Every active object has a single entry point defining a fixed set of messages that are understood. Passive objects are the objects that are actually sent between actors, and are copied around to guarantee isolation. This enables a separation of concerns between data that relates to actor communication and data that relates to actor state and behavior.
The active object model as initially described in the ABCL/1 language defines objects with a state and three modes:
dormant: Initial state of no computation, simply waiting for a message to activate the behavior of the actor.active: A state in which computation is performed that is triggered when a message is received that satisfies the patterns and constraints that the actor has defined it can process.waiting: A state of blocked execution, where the actor is active, but waiting until a certain type or pattern of message arrives to continue computation.
ABCL/1 Language
The ABCL/1 language implements the active object model described above, representing a system as a collection of objects, and the interactions between those objects as concurrent messages being passed around. (Yonezawa, Briot, & Shibayama, 1986) One interesting aspect of ABCL/1 is the idea of explicitly different modes of message passing. Other actor models generally have a notion of priority around the values, types, or patterns of messages they process, usually defined by the ordering of their receive operation, but ABCL/1 implements two different modes of message passing with different semantics. They have standard queued messages in the ordinary mode, but more interestingly they have express priority messages. When an object receives an express message it halts any other processing of ordinary messages it is performing, and processes the express message immediately. This enables an actor to accept high-priority messages while in active mode, and also enables monitoring and interrupting actors.
The language also offers different models of synchronization around message-passing between actors. Three different message-passing models are given that enable different use cases:
past: Requests another actor to perform a task, while simultaneously proceeding with computation without waiting for the task to be completed.now: Waits for a message to be received, and to receive a response. This acts as a basic synchronization barrier across actors.future: Acts like a typical future, continuing computation until a remote result is needed, and then blocking until that result is received.
It is interesting to note that all of these modes can be expressed by the past style of message-passing, as long as the type of the message and which actor to reply to with results are known.
The key difference here is around how this different style of actors relates to managing their lifecycle. In the active object style, lifecycle is a result of messages or requests to actors, but in other styles we see a more explicit notion of lifecycle and creating/destroying actors.
Orleans
Orleans takes the concept of actors whose lifecycle is dependent on messaging or requests and places them in the context of cloud applications. (Bykov et al., 2011) Orleans does this via actors (called “grains”) which are isolated units of computation and behavior that can have multiple instantiations (called “activations”) for scalability. These actors also have persistence, meaning they have a persistent state that is kept in durable storage so that it can be used to manage things like user data.
Orleans uses a different notion of identity than other actor systems. In other systems an “actor” might refer to a behavior and instances of that actor might refer to identities that the actor represents like individual users. In Orleans, an actor represents that persistent identity, and the actual instantiations are in fact reconcilable copies of that identity.
The programmer essentially assumes that a single entity is handling requests to an actor, but the Orleans runtime actually allows for multiple instantiations for scalability. These instantiations are invoked in response to an RPC-like call from the programmer which immediately returns an asynchronous promise.
In Orleans, declaring an actor just looks like making any other class which implements a specific interface. A simple example here is a PlayerGrain which can join games. All methods of an Orleans actor (grain) interface must return a Task<T>, as they are all asynchronous.
public interface IPlayerGrain : IGrainWithGuidKey
{
Task<IGameGrain> GetCurrentGame();
Task JoinGame(IGameGrain game);
}
public class PlayerGrain : Grain, IPlayerGrain
{
private IGameGrain currentGame
public Task<IGameGrain> GetCurrentGame()
{
return Task.FromResult(currentGame);
}
public Task JoinGame(IGameGrain game)
{
currentGame = game;
Console.WriteLine("Player {0} joined game {1}", this.GetPrimaryKey(), game.GetPrimaryKey());
return TaskDone.Done;
}
}
Invoking a method on an actor is done like any other asynchronous call, using the await keyword in C#. This can be done from either a client or inside another actor (grain). In both cases the call looks almost exactly the same, the only different being clients use GrainClient.GrainFactory while actors can use GrainFactory directly.
IPlayerGrain player = GrainClient.GrainFactory.GetGrain<IPlayerGrain>(playerId);
Task joinGameTask = player.JoinGame(currentGame);
await joinGameTask;
Here a game client gets a reference to a specific player, and has that player join the current game. This code looks like any other asynchronous C# code a developer would be used to writing, but this is really an actor system where the runtime has abstracted away many of the details. The runtime handles all of the actor lifecycle in response to the requests clients and other actors within the system make, as well as persistence of state to long-term storage.
Multiple instances of an actor can be running and modifying the state of that actor at the same time. The immediate question here is how does that actually work? It doesn’t intuitively seem like transparently accessing and changing multiple isolated copies of the same state should produce anything but problems when its time to do something with that state.
Orleans solves this problem by providing mechanisms to reconcile conflicting changes. If multiple instances of an actor modify persistent state, they need to be reconciled into a consistent state in some meaningful way. The default here is a last-write-wins strategy, but Orleans also exposes the ability to create fine-grained reconciliation policies, as well as a number of common reconcilable data structures. If an application requires a certain reconciliation algorithm, the developer can implement it using Orleans. These reconciliation mechanisms are built upon Orleans’ concept of transactions.
Transactions in Orleans are a way to causally reason about the different instances of actors that are involved in a computation. Because in this model computation happens in response to a single outside request, a given actor’s chain of computation via. associated actors always contains a single instantiation of each actor. These causal chain of instantiations is treated as a single transaction. At reconciliation time Orleans uses these transactions, along with current instantiation state to reconcile to a consistent state.
All of this is a longwinded way of saying that Orleans’ programmer-centric contributions are that it separates the concerns of running and managing actor lifecycles from the concerns of how data flows throughout your distributed system. It does this is a fault-tolerant way, and for many programming tasks, you likely wouldn’t have to worry about scaling and reconciling data in response to requests. It provides the benefits of the actor model through a programming model that attempts to abstract away details that you would otherwise have to worry about when using actors in production.
Why the actor model?
The actor programming model offers benefits to programmers of distributed systems by allowing for easier programmer reasoning about behavior, providing a lightweight concurrency primitive that naturally scales across many machines, and enabling looser coupling among components of a system allowing for change without service disruption. Actors enable a programmer to easier reason about their behavior because they are at a fundamental level isolated from other actors. When programming an actor, the programmer only has to worry about the behavior of that actor and the messages it can send and receive. This alleviates the need for the programmer to reason about an entire system. Instead the programmer has a fixed set of concerns, meaning they can ensure behavioral correctness in isolation, rather than having to worry about an interaction they hadn’t anticipated occurring. Actors provide a single means of communication (message-passing), meaning that a lot of concerns a programmer has around concurrent modification of data are alleviated. Data is restricted to the data within a single actor and the messages it has been passed, rather than all of the accessible data in the whole system.
Actors are lightweight, meaning that the programmer usually does not have to worry about how many actors they are creating. This is a contrast to other fundamental units of concurrency like threads or processes, which a programmer has to be acutely aware of, as they incur high costs of creation, and quickly run into machine resource and performance limitations.
Without a lightweight process abstraction, users are often forced to write parts of concurrent applications in an event-driven style which obscures control flow, and increases the burden on the programmer.
Unlike threads and processes, actors can also easily be told to run on other machines as they are functionally isolated. This cannot traditionally be done with threads or processes, as they are unable to be passed over the network to run elsewhere. Messages can be passed over the network, so an actor does not have to care where it is running as long as it can send and receive messages. They are more scalable because of this property, and it means that actors can naturally be distributed across a number of machines to meet the load or availability demands of the system.
Finally, because actors are loosely coupled, only depending on a set of input and output messages to and from other actors, their behavior can be modified and upgraded without changing the entire system. For example, a single actor could be upgraded to use a more performant algorithm to do its work, and as long as it can process the same input and output messages, nothing else in the system has to change. This isolation is a contrast to methods of concurrent programming like remote procedure calls, futures, and promises. These models emphasize a tighter coupling between units of computation, where a process may call a method directly on another process and expect a specific result. This means that both the caller and callee (receiver of the call) need to have knowledge of the code being run, so you lose the ability to upgrade one without impacting the other. This becomes a problem in practice, as it means that as the complexity of your distributed system grows, more and more pieces become linked together.
It is important to note that the actor languages give special emphasis to developing flexible program structures which simplify reasoning about programs.
This is not desirable, as a key characteristic of distributed systems is availability, and the more things are linked together, the more of your system you have to take down or halt to make changes/upgrades. Actors compare favorably to other concurrent programming primitives like threads or remote procedure calls due to their low cost and loosely coupled nature. They are also programmer friendly, and ease the programmer burden of reasoning about a distributed system.
Modern usage in production
It is important when reviewing models of programming distributed systems not to look just to academia, but to see which of these systems are actually used in industry to build things. This can give us insight into which features of actor systems are actually useful, and the trends that exist throughout these systems.
On the Integration of the Actor Model in Mainstream Technologies: The Scala Perspective (Haller, 2012) provides some insight into the requirements of an industrial-strength actor implementation on a mainstream platform. These requirements were drawn out of an initial effort with Scala Actors to bring the actor model to mainstream software engineering, as well as lessons learned from the deployment and advancement of production actors in Akka.
- Library-based implementation: It is not obvious which concurrency abstraction wins in real world cases, and different concurrency models might be used to solve different problems, so implementing a concurrency model as a library enables flexibility in usage.
- High-level domain-specific language: A domain-specific language or something comparable is a requirement to compete with languages that specialize in concurrency, otherwise your abstractions are lacking in idioms and expressiveness.
- Event-driven implementation: Actors need to be lightweight, meaning they cannot be mapped to an entire VM thread or process. For most platforms this means an event-driven model.
- High performance: Most industrial applications that use actors are highly performance sensitive, and high performance enables more graceful scalability.
- Flexible remote actors: Many applications can benefit from remote actors, which can communicate transparently over the network. Flexibility in deployment mechanisms is also very important.
These attributes give us a good basis for analyzing whether an actor system can be successful in production. These are attributes that are necessary, but not sufficient for an actor system to be useful in production.
Failure handling
One of the most important concepts and reasons people use actor systems in production is their support for failure handling and recovery. The root of this support is the previously mentioned ability for actors to supervise one another, and to have supervisors notified of failures. Designing Reactive Systems: The Role of Actors in Distributed Architecture (McKee, 2016) details four well-known recovery steps that a supervising actor may take when they are notified of a problem with one of their workers.
- Ignore the error and let the worker resume processing
- Restart the worker and reset their state
- Stop the worker entirely
- Escalate the problem to the supervisor’s supervising actor
Based on this scheme, all actors within a system will have a supervisor, which amounts to a large tree of supervision. At the top of the tree is the actor system itself, which may have a default recovery scheme like simply restarting the actor. An interesting note is that this frees up individual actors from handling their failures. The philosophy around failure shifts to “actors will fail” and that we need other explicit actors and methods for handling failure outside of the business logic of the individual actor.

Another approach that naturally falls out of supervision heirarchies, is that they can be distributed across machines (nodes) within a cluster of actors for fault tolerance.
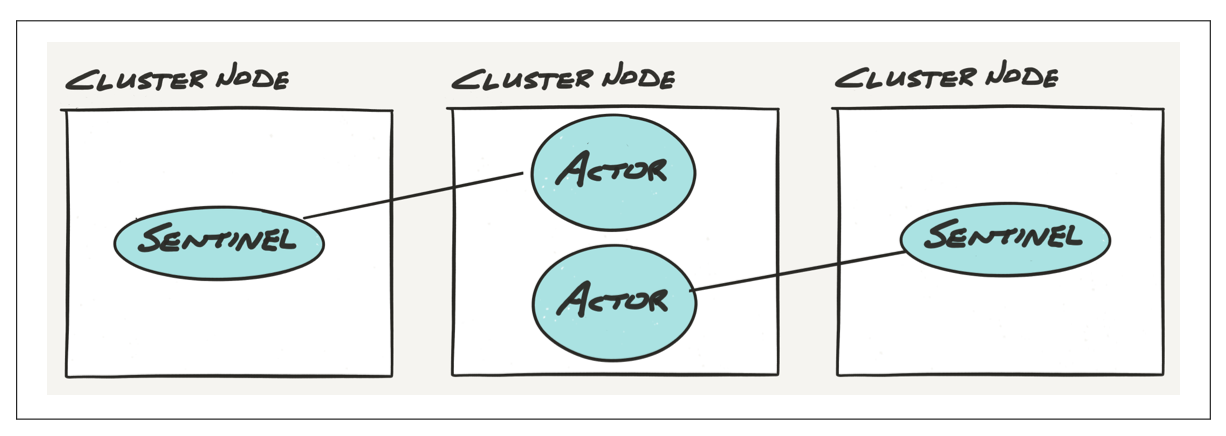
Critical actors can be monitored across nodes, which means that failures can be detected across nodes within a cluster. This allows for other actors within the cluster to easily react to the entire state of the system, not just the state of their local machine. This is important for a number of problems that arise in distributed systems like load-balancing and data/request partitioning. This also allows naturally allows for some form of recovery from the other machines within a cluster, such as spinning up another node automatically or restarting the failed machine/node.
Flexibility around failure handling is a key advantage of using actors in production systems. Supervision means that worker actors can focus on business logic, and failure-handling actors can focus on managing and recovering those actors. Actors can also be cluster-aware and have a view into the state of the entire distributed system.
Actors as a framework
One trend that seems common among the actor systems we see in production is extensive environments and tooling. Akka, Erlang, and Orleans are the primary actor systems that see real production use, and the reason for this is that they essentially act as frameworks where many of the common problems of actors are taken care of for you. They offer support for managing and monitoring the deployment of actors as well as patterns or modules to handle problems like fault-tolerance and load balancing which every distributed actor system has to address. This allows the programmer to focus on the problems within their domain, rather than the common problems of monitoring, deployment, and composition.
Akka and Erlang provide modules that you can piece together to build various pieces of functionality into your system. Akka provides a huge number of modules and extensions to configure and monitor a distributed system built using actors. They provide a number of utilities to meet common use-case and deployment scenarios, and these are thoroughly listed and documented. For example Akka includes modules to deal with the following common issues (and more):
- Fault Tolerance via supervision hierarchies
- Routing to balance load across actors
- Persistence to save and recover actor state across failures and restarts
- A testing framework specifically for actors
- Cluster management to group and distribute actors across physical machines
Additionally they provide support for Akka Extensions, which are a mechanism for adding your own features to Akka. These are powerful enough that some core features of Akka like Typed Actors or Serialization are implemented as Akka Extensions.
Erlang provides the Open Telecom Platform (OTP), which is a framework comprised of a set of modules and standards designed to help build applications. OTP takes the generic patterns and components of Erlang, and provides them as libraries that enable code reuse and best practices when developing new systems. Some examples of OTP libraries are:
- A real-time distributed database
- An interface to relational databases
- A monitoring framework for machine resource usage
- Support for interfacing with other communication protocols like SSH
- A test framework
Cloud Haskell also provides something analogous to Erlang’s OTP called the Cloud Haskell Platform.
Orleans is different from these as it is built from the ground up with a more declarative style and runtime. This does a lot of the work of distributing and scaling actors for you, but it is still definitely a framework which handles a lot of the common problems of distribution so that programmers can focus on building the logic of their system. Orleans takes care of the distribution of actors across machines, as well as creating new actor instances to handle increased load. Additionally, Orleans also deals with reconciliation of consistency issues across actor instantiations, as well as persistence of actor data to durable storage. These are common issues that the other industrial actor frameworks also address in some capacity using modules and extensions.
Module vs. managed runtime approaches
Based on my research there have been two prevalent approaches to frameworks which are actually used to build production actor systems in industry. These are high-level philosophies about the meta-organization of an actor system. They are the design philosophies that aren’t even directly considered when just looking at the base actor programming and execution models. The easiest way to describe these is are as the “module approach” and the “managed runtime approach”. A high-level analogy to describe these is that the module approach is similar to manually managing memory, while the managed runtime approach is similar to garbage collection. In the module approach, you care about the lifecycle and physical allocation of actors within your system, while in the managed runtime approach you care more about the reconciliation behavior and flow of persistent state between automatic instantiations of your actors.
Both Akka and Erlang take a module approach to building their actor systems. This means that when you build a system using these languages/frameworks, you are using smaller composable components as pieces of the larger system you want to build. You are explicitly dealing with the lifecycles and instantiations of actors within your system, where to distribute them across physical machines, and how to balance actors to scale. Some of these problems might be handled by libraries, but at some level you are specifying how all of the organization of your actors is happening. The JVM or Erlang VM isn’t doing it for you.
Orleans goes in another direction, which I call the managed runtime approach. Instead of providing small components which let you build your own abstractions, they provide a runtime in the cloud that attempts to abstract away a lot of the details of managing actors. It does this to such an extent that you no longer even directly manage actor lifecycles, where they live on machines, or how they are replicated and scaled. Instead you program with actors in a more declarative style. You never explicitly instantiate actors, instead you assume that the runtime will figure it out for you in response to requests to your system. You program in strategies to deal with problems like domain-specific reconciliation of data across instances, but you generally leave it to the runtime to scale and distribute the actor instances within your system.
Both approaches have been successful in industry. Erlang has the famous use case of a telephone exchange and a successful history since then. Akka has an entire page detailing its usage in giant companies. Orleans has been used as a backend to massive Microsoft-scale games and applications with millions of users. It seems like the module approach is more popular, but there’s only really one example of the managed runtime approach out there. There’s no equivalent to Orleans on the JVM or Erlang VM, so realistically it doesn’t have as much exposure in the distributed programming community.
Comparison to Communicating Sequential Processes
One popular model of message-passing concurrency that has been getting attention is Communicating Sequential Processes (CSP). The basic idea behind CSP is that concurrent communication between processes is done by passing messages through channels. Arguably the most popular modern implementation of this is Go’s channels. A lot of the surface-level discussions of actors simply take them as something that is a lightweight concurrency primitive which passes messages. This zoomed-out view might conflate CSP-style channels and actors, but it misses a lot of subtleties as CSP really can’t be considered an actor framework. The core difference is that CSP implements some form of synchronous messaging between processes, while the actor model entirely decouples messaging between a sender and a receiver. Actors are much more independent, meaning its easier to run them in a distributed environment without changing their semantics. Additionally, receiver failures don’t affect senders in the actor model. Actors are a more loosely-coupled abstraction across a distributed environment, while CSP embraces tight-coupling as a means of synchronization across processes. To conflate the two misses the point of both, as actors are operating at a fundamentally different level of abstraction from CSP.
References
- De Koster, J., Van Cutsem, T., & De Meuter, W. (2016). 43 Years of Actors: A Taxonomy of Actor Models and Their Key Properties. In Proceedings of the 6th International Workshop on Programming Based on Actors, Agents, and Decentralized Control (pp. 31–40). New York, NY, USA: ACM. http://doi.org/10.1145/3001886.3001890
- Yonezawa, A., Briot, J.-P., & Shibayama, E. (1986). Object-oriented Concurrent Programming in ABCL/1. SIGPLAN Not., 21(11), 258–268. http://doi.org/10.1145/960112.28722
- Dedecker, J., Van Cutsem, T., Mostinckx, S., D'Hondt, T., & De Meuter, W. (2006). Ambient-Oriented Programming in Ambienttalk. In Proceedings of the 20th European Conference on Object-Oriented Programming (pp. 230–254). Berlin, Heidelberg: Springer-Verlag. http://doi.org/10.1007/11785477_16
- Cutsem, T. V., Mostinckx, S., Boix, E. G., Dedecker, J., & Meuter, W. D. (2007). AmbientTalk: Object-oriented Event-driven Programming in Mobile Ad Hoc Networks. In Proceedings of the XXVI International Conference of the Chilean Society of Computer Science (pp. 3–12). Washington, DC, USA: IEEE Computer Society. http://doi.org/10.1109/SCCC.2007.4
- McKee, H. (2016). Designing Reactive Systems: The Role of Actors in Distributed Architecture.
- Miller, M. S., Tribble, E. D., & Shapiro, J. (2005). Concurrency Among Strangers: Programming in E As Plan Coordination. In Proceedings of the 1st International Conference on Trustworthy Global Computing (pp. 195–229). Berlin, Heidelberg: Springer-Verlag. Retrieved from http://dl.acm.org/citation.cfm?id=1986262.1986274
- Agha, G. (1990). Concurrent Object-oriented Programming. Commun. ACM, 33(9), 125–141. http://doi.org/10.1145/83880.84528
- Armstrong, J. (2010). Erlang. Commun. ACM, 53(9), 68–75. http://doi.org/10.1145/1810891.1810910
- Haller, P. (2012). On the Integration of the Actor Model in Mainstream Technologies: The Scala Perspective. In Proceedings of the 2Nd Edition on Programming Systems, Languages and Applications Based on Actors, Agents, and Decentralized Control Abstractions (pp. 1–6). New York, NY, USA: ACM. http://doi.org/10.1145/2414639.2414641
- Hewitt, C., Bishop, P., & Steiger, R. (1973). A Universal Modular ACTOR Formalism for Artificial Intelligence. In Proceedings of the 3rd International Joint Conference on Artificial Intelligence (pp. 235–245). San Francisco, CA, USA: Morgan Kaufmann Publishers Inc. Retrieved from http://dl.acm.org/citation.cfm?id=1624775.1624804
- Cutsem, T. V., Boix, E. G., Scholliers, C., Carreton, A. L., Harnie, D., Pinte, K., & Meuter, W. D. (2014). AmbientTalk: programming responsive mobile peer-to-peer applications with actors. Computer Languages, Systems and Structures, SCI Impact Factor in 2013: 0.296, 5 Year Impact Factor 0.329 (to Appear).
- Bykov, S., Geller, A., Kliot, G., Larus, J. R., Pandya, R., & Thelin, J. (2011). Orleans: Cloud Computing for Everyone. In Proceedings of the 2Nd ACM Symposium on Cloud Computing (pp. 16:1–16:14). New York, NY, USA: ACM. http://doi.org/10.1145/2038916.2038932
- Tomlinson, C., Kim, W., Scheevel, M., Singh, V., Will, B., & Agha, G. (1988). Rosette: An Object-oriented Concurrent Systems Architecture. SIGPLAN Not., 24(4), 91–93. http://doi.org/10.1145/67387.67410
- Haller, P., & Odersky, M. (2009). Scala Actors: Unifying Thread-based and Event-based Programming. Theor. Comput. Sci., 410(2-3), 202–220. http://doi.org/10.1016/j.tcs.2008.09.019
- Epstein, J., Black, A. P., & Peyton-Jones, S. (2011). Towards Haskell in the cloud. In Proceedings of the 4th ACM symposium on Haskell (pp. 118–129). New York, NY, USA: ACM. http://doi.org/10.1145/2034675.2034690
- Agha, G. (1986). Actors: A Model of Concurrent Computation in Distributed Systems. Cambridge, MA, USA: MIT Press.
- Peierls, T., Goetz, B., Bloch, J., Bowbeer, J., Lea, D., & Holmes, D. (2005). Java Concurrency in Practice. Addison-Wesley Professional.
- McCaffrey, C. (2015). Building the Halo 4 Services with Orleans. Retrieved from https://www.infoq.com/presentations/halo-4-orleans
- Reed, R. (2012). Scaling to Millions of Simultaneous Connections. Retrieved from https://vimeo.com/44312354
- Sucharitakul, A. (2016). squbs: A New, Reactive Way for PayPal to Build Applications. Retrieved from https://www.paypal-engineering.com/2016/05/11/squbs-a-new-reactive-way-for-paypal-to-build-applications/
- Kay, A. (1998). prototypes vs classes was: Re: Sun’s HotSpot. Retrieved from http://lists.squeakfoundation.org/pipermail/squeak-dev/1998-October/017019.html